 LOTUS: Learning Universal Task Representations for Reinforcement Learning with Temporal Logic Guidance
LOTUS: Learning Universal Task Representations for Reinforcement Learning with Temporal Logic Guidance
Abstract
Task guided agents demonstrate strong performance in a wide range of complex tasks. However, most existing task representation algorithms are tailored to specific contexts and struggle to generalize across diverse scenarios. Moreover, they typically depend on gradient signals from reinforcement learning controllers to update their weights, which can degrade both representation quality and learning efficiency.
To overcome these limitations, we propose LOTUS, a temporal logic inspired universal task representation framework that can be seamlessly integrated into any RL algorithm to enhance agent performance across diverse task settings. Specifically, we design a novel task representation architecture capable of modeling relationships and extracting task semantics from LTL formulas. We further introduce a more effective update mechanism that treats the LTL encoder as a policy, thereby improving representation capacity. To enhance stability and robustness, LOTUS leverages the bisimulation metric, which provides theoretical guarantees for LTL representation, including behavioral equivalence, optimality fidelity, and trajectory robustness.
Experimental results show that LOTUS outperforms most existing methods in learning efficiency, generalization capability, and representation quality.
Methods
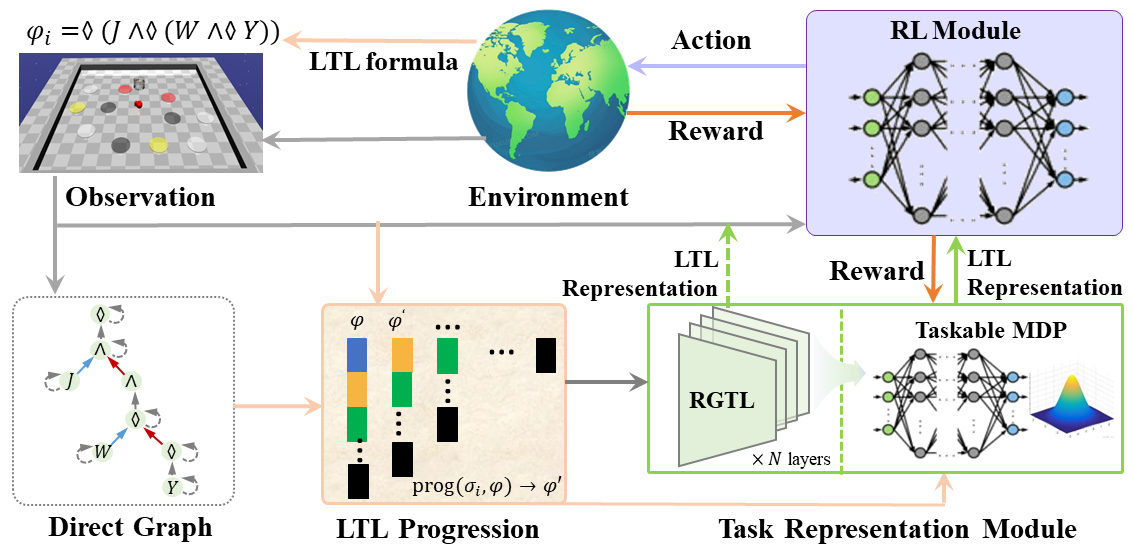
Overview. The framework of LOTUS.
Simulation Results
ZoneEnv
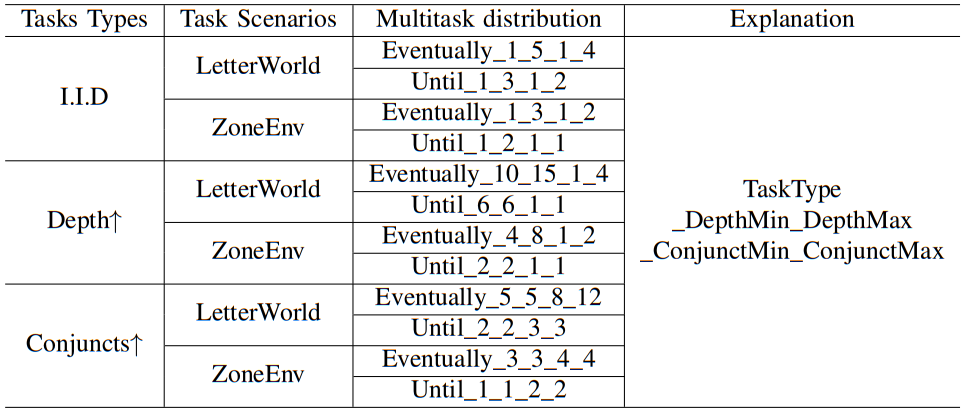
In ZoneEnv and LetterWorld scenarios, we sample different LTL tasks from the same multi-task distribution in every episode. For example, the sampled task can be $\lozenge(\mathrm{Black}\wedge\lozenge(\mathrm{White}\wedge\lozenge\mathrm{Red}))$ when the agent perfoming "Eventually_1_3_1_2", where "Eventually" means the task kind, "1_3" means the interval of subgoal depth can be sampled, and "1_2" is the interval of task conjuncts can be sampled.
I. Definition of the label format: In "Eventually_1_3_1_2", each part has the following meaning:
- "Eventually": Indicates the task type is "eventually-achieved" (corresponding to the ◇ operator in LTL), meaning the agent only needs to satisfy the target condition at some point in the trajectory, without maintaining it continuously.
-
"1_3": Represents the sampling interval of subgoal depth, i.e., the number of nested subgoal layers of this type of task will be randomly generated between 1 and 3. For example:
- Depth 1: Only a single goal needs to be achieved (e.g., "eventually grasp the red cube");
- Depth 2: Subgoal A must be achieved first, then goal B (e.g., "eventually push the box to the designated area, and eventually grasp the cup");
- Depth 3: Subgoal A → Subgoal B → Goal C must be achieved in sequence (e.g., "eventually approach the table, and eventually pick up the tool, and eventually complete the assembly").
-
"1_2": Represents the sampling interval of the number of task conjuncts, i.e., the number of parallel goals included in this type of task will be randomly generated between 1 and 2 (corresponding to the ∧ operator in LTL). For example:
- 1 conjunct: A single parallel goal (e.g., "eventually turn on the faucet");
- 2 conjuncts: Two parallel goals must be satisfied simultaneously (e.g., "eventually turn on the faucet, and eventually close the valve").
II. Explanation of task setting labels in the tables:
- i.i.d (Independent and Identically Distributed): Indicates "independent and identically distributed" task setting. Test tasks follow the same distribution as training tasks, with subgoal depth and number of conjuncts within the regular range during training (e.g., the above "1_3" and "1_2" intervals), used to verify basic generalization ability.
- Depth (↑): Indicates "subgoal depth enhancement" setting, where "↑" denotes increased depth values (exceeding the regular interval during training), used to verify the algorithm's generalization ability in more complex nested tasks. For example, if the training depth interval is 1_3, the test interval may extend to 4_6, requiring the agent to handle more hierarchical subgoal dependencies.
- Conjuncts (↑): Indicates "number of conjuncts enhancement" setting, where "↑" denotes an increased number of conjuncts (exceeding the regular interval during training), used to verify the algorithm's generalization ability in scenarios with multiple parallel goals. For example, if the training conjunct interval is 1_2, the test interval may extend to 3_4, requiring the agent to satisfy more parallel target conditions simultaneously.
Partilly-Ordered Task (I.I.D)
Avoidance Task (I.I.D)

The performance (Our LOTUS) in the multi-task scenario with Eventually_1_3_1_2 task distribution.

The performance (Our LOTUS) in the multi-task scenario with Until_1_2_1_1 task distribution.
Partilly-Ordered Task (Depth)
Avoidance Task (Depth)
The performance (Our LOTUS) in the multi-task scenario with Eventually_4_8_1_2 task distribution.

The performance (Our LOTUS) in the multi-task scenario with Until_2_2_1_1 task distribution.
Partilly-Ordered Task (Conjuncts)
Avoidance Task (Conjuncts)
The performance (Our LOTUS) in the multi-task scenario with Eventually_3_3_4_4 task distribution.

The performance (Our LOTUS) in the multi-task scenario with Until_1_1_2_2 task distribution.
Robosuite

Robosuite-Stack


Successful Demo of Stack Task (Our LOTUS) and its corresponding snapshots with key task progression.

Task completion demos under different initial distributions of objects in Stack task (Our LOTUS).
Robosuite-Nut Assembly


Successful Demo of Task Nut Assembly (Our LOTUS) and its corresponding snapshots with key task progression.

Task completion demos under different initial distributions of objects in Task Nut Assembly (Our LOTUS).
Robosuite-Cleanup

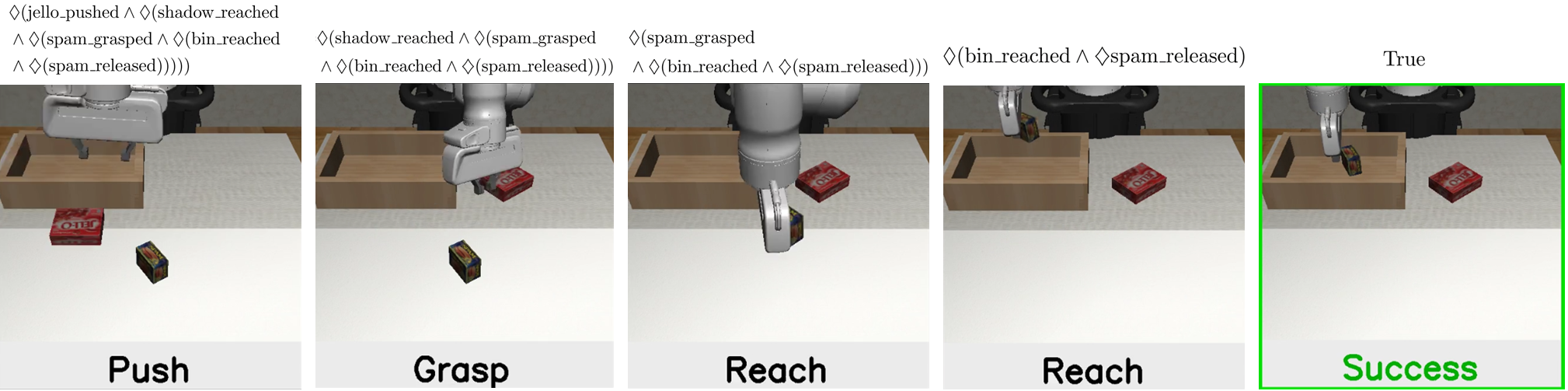
Successful Demo of Task Cleanup (Our LOTUS) and its corresponding snapshots with key task progression.

Task completion demos under different initial distributions of objects in Task Cleanup (Our LOTUS).
Robosuite-Peg Insertion


Successful Demo of Task Peg Insertion (Our LOTUS) and its corresponding snapshots with key task progression.

Task completion demos under different initial distributions of objects in Task Peg Insertion (Our LOTUS).
DexArt

Toilet
Seen
Unseen

Manipulation Performance (Our LOTUS) in Toilet task with the seen set.

Manipulation Performance (Our LOTUS) in Toilet task with the unseen set.
Real-world Performance
Stack

Snapshots of Stack task with key task progression in the Real-world performance (Our LOTUS).


Task completion demos under different initial distributions of objects in Stack task (Our LOTUS).
Cleanup

Snapshots of Cleanup task with key task progression in the Real-world performance (Our LOTUS).


Task completion demos under different initial distributions of objects in Cleanup task (Our LOTUS).
Appendix
Symbol Apointment

Task Scenarios, task description and corresponding LTL formulas in Example

The Descriptions of LTL Specifications in Trajectory Visualization

BibTeX
This website template is borrowed from Nerfies